
Leslie A. Pray, Ph.D. © 2008 Nature Education
Trích dẫn: Pray, L. (2008) Sự sao chép DNA và nguyên nhân đột biến. Nature Education 1 (1): 214
Người dịch: Lê Nguyễn
Lời giới thiệu: Cấu trúc RNA của các vi rút rất giống DNA ở các sinh vật khác. Trong quá trình sinh sản, việc sao chép RNA cũng có thể bị lỗi như sao chép DNA và gây ra đột biến. Bài viết này chú trọng vào lỗi sao chép DNA và nguyên nhân gây đột biến, nhưng cũng giúp giải đáp thắc mắc về biến thể vi rút. Bài viết giải thích việc sao chép DNA cũng như khả năng bị lỗi của quá trình đó và việc sửa chữa cho nó.
(Bài này mang nội dung chuyên môn cao, nhưng rất có ích cho những ai đang quan tâm các biến thể Corona hiện đang là vấn đề thời sự với biến thể Omicron. Độc giả không chuyên môn cứ việc bỏ qua các sơ đồ hóa học là cũng có thể theo dõi được).
***
Tế bào sử dụng một kho các cơ chế chỉnh sửa để sửa chữa những sai lầm mắc phải trong quá trình sao chép DNA.Chúng hoạt động như thế nào và điều gì sẽ xảy ra khi các hệ thống này bị lỗi?
Sao chép DNA là một hiện tượng sinh học thực sự đáng kinh ngạc. Hãy xem xét vô số lần tế bào của bạn phân chia để tạo nên cơ thể của bạn — không chỉ trong quá trình phát triển , mà ngay cả lúc đã là một người trưởng thành hoàn toàn. Sau đó, hãy xem xét rằng mỗi khi tế bào người phân chia và DNA của nó nhân đôi, nó phải sao chép và truyền cùng một trình tự chính xác gồm 3 tỷ nucleotide cho các tế bào con của nó. Cuối cùng, hãy xem xét một thực tế rằng trong cuộc sống (theo nghĩa đen), không có gì là hoàn hảo. Mặc dù hầu hết DNA sao chép với độ trung thực khá cao, nhưng các sai lầm vẫn xảy ra, với các enzyme polymerase đôi khi chèn nhầm nucleotide hoặc quá nhiều hoặc quá ít nucleotide vào một trình tự.May mắn thay, hầu hết những sai lầm này được sửa chữa thông qua nhiều quy trình sửa chữa DNA [1].Các enzyme sửa chữa nhận ra sự không hoàn hảo về cấu trúc giữa các nucleotide được ghép nối không đúng cách, cắt bỏ những nucleotide sai và đưa những nucleotide đúng vào vị trí của chúng. Nhưng một số lỗi sao chép vượt qua những cơ chế này, do đó trở thành đột biến vĩnh viễn. Sau đó, những trình tự nucleotide bị thay đổi này có thể được truyền từ thế hệ tế bào này sang thế hệ tế bào khác, và nếu chúng xảy ra trong các tế bào phát sinh giao tử (gametes hay sex cells), chúng thậm chí có thể được truyền sang các thế hệ sinh vật tiếp theo. Hơn nữa, khi bản thân các gen của các enzyme sửa chữa DNA bị đột biến, các sai lầm bắt đầu tích tụ với tốc độ cao hơn nhiều. Ở sinh vật đa bào với tế bào có nhân (eukaryotes), những đột biến như vậy có thể dẫn đến ung thư [2].
Lỗi là một phần tự nhiên của quá trình sao chép DNA
Sau khi James Watson và Francis Crick[3] công bố mô hình của họ về cấu trúc chuỗi xoắn kép của DNA vào năm 1953, các nhà sinh vật học ban đầu suy đoán rằng hầu hết các lỗi sao chép là do những gì được gọi là dịch chuyển đồng dạng gây ra. Cả hai gốc purine và pyrimidine trong DNA đều tồn tại ở các dạng hóa học khác nhau, hoặc dạng đồng phân biến đổi, trong đó các proton chiếm các vị trí khác nhau trong phân tử (Hình 1).Mô hình Watson-Crick đòi hỏi nucleotidebazơ ở dạng “keto” phổ biến hơn của chúng (Watson & Crick, 1953). Các nhà khoa học tin rằng nếu và khi một cơ sở nucleotide chuyển sang dạng tautomeric hiếm hơn của nó (dạng “imino” hoặc “enol”), thì một kết quả có thể xảy ra là cặp bazơ không khớp. Nhưng bằng chứng cho những loại dịch chuyển đồng dạng này vẫn còn thưa thớt.
Một sơ đồ nhiều bảng cho thấy cách các nucleotide hình thành các mối quan hệ cặp bazơ khác nhau khi chúng tồn tại ở các dạng hóa học khác nhau.Trong bảng a, cấu trúc phân tử của nucleotide thymine, guanine, cytosine và adenine được hiển thị trong hai cột: cột bên trái hiển thị bốn nucleotide ở dạng phổ biến và cột bên phải hiển thị bốn nucleotide ở dạng hiếm. Một mũi tên cong màu đỏ cho biết vị trí các proton dịch chuyển trên cấu trúc chung để tạo ra đồng phân tautomer hiếm. Bảng b cho thấy sự sắp xếp cặp bazơ chung giữa các cấu trúc hóa học chung của thymine và adenine và giữa cytosine và guanine. Bảng c cho thấy sự sắp xếp hiếm giữa các cấu trúc hóa học chung của cytosine và adenine và giữa thymine và guanine.

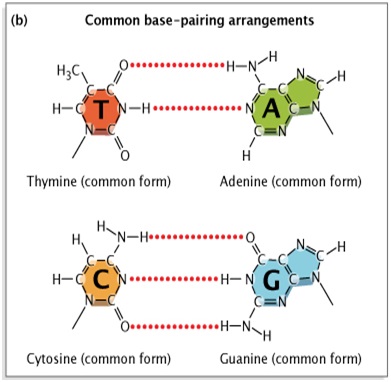

Hình 1: Sự dịch chuyển đồng phân trong các bazơ nucleotide.
Các gốc purine và pyrimidine trong DNA tồn tại ở hai dạng biến đổi hoặc dạng hóa học khác nhau. (Bảng a): Các bazơ nucleotide chuyển từ dạng “xeto” phổ biến sang dạng “enol” hiếm hơn, đồng phân của chúng. (Bảng b): Trong cách sắp xếp cặp bazơ chung, dạng chung của thymine (T) liên kết với dạng chung của adenine (A), và dạng chung của cytosine (C) liên kết với dạng chung của guanine (G). (Bảng c): Sự sắp xếp cặp bazơ hiếm xảy ra khi một nucleotide trong cặp bazơ là dạng hiếm thay vì dạng phổ biến. Ở đây, dạng cytosine hiếm liên kết với dạng phổ biến của adenine thay vì guanine.Dạng hiếm của guanine liên kết với dạng phổ biến của thymine thay vì cytosine.
© 2014 Nature Education[4] phỏng theo Pierce, Benjamin. Di truyền học: Phương pháp tiếp cận khái niệm , xuất bản lần thứ 2. Đã đăng ký Bản quyền.
Ngày nay, các nhà khoa học nghi ngờ rằng hầu hết các lỗi sao chép DNA là do sự nhầm lẫn có bản chất khác nhau: giữa các dạng bazơ khác nhau nhưng không đồng phân hóa học (ví dụ: bazơ có thêm một proton, vẫn có thể liên kết nhưng thường là với một nucleotide không khớp, chẳng hạn như A với G thay vì T) hoặc giữa các bazơ “bình thường” nhưng vẫn liên kết không thích hợp (ví dụ, một lần nữa, A với G thay vì T) do có sự dịch chuyển nhẹ vị trí của các nucleotide trong không gian (Hình 2). Loại sai sót này được gọi là lung lay . Nó xảy ra bởi vì chuỗi xoắn kép DNA linh hoạt và có thể chứa các cặp đôi hơi sai hình thức (Crick, 1966)
Một sơ đồ cho thấy hai cặp bazơ nucleotide có sự dao động.Bên trên, cấu trúc hóa học của bazơ thymine (màu đỏ) được kết nối với cấu trúc hóa học của bazơ guanine (màu xanh lam) bằng hai liên kết hydro.Các liên kết hydro được mô tả dưới dạng các đường đứt nét màu đỏ.Bên dưới, cấu trúc hóa học của cytosine cơ bản (màu cam) được kết nối với cấu trúc hóa học của base adenine (màu xanh lá cây) bằng hai liên kết hydro.

Hình 2: Sự lung lay trong các cặp bazơ nucleotide không khớp.
Sự thay đổi vị trí của các nucleotide gây ra sự xáo trộn giữa thymine bình thường và guanine bình thường. Một proton bổ sung trên adenine gây ra sự chao đảo trong cặp bazơ adenine-cytosine.
© Nature Education phỏng theo Pierce, Benjamin. Di truyền học: Phương pháp tiếp cận khái niệm, xuất bản lần thứ 2. Đã đăng ký Bản quyền.
Lỗi sao chép cũng có thể liên quan đến việc chèn hoặc xóa các cơ sở nucleotide xảy ra trong một quá trình được gọi là trượt sợi . Đôi khi, một sợi mới được tổng hợp vòng ra một chút, dẫn đến việc bổ sung thêm một cơ sở nucleotide (Hình 3). Những lần khác, sợi khuôn vòng ra ngoài một chút, dẫn đến việc bỏ sót hoặc loại bỏ một cơ sở nucleotide trong sợi mới được tổng hợp, hoặc đoạn mồi.Các vùng DNA chứa nhiều bản sao của các trình tự nhỏ lặp lại đặc biệt dễ mắc phải lỗi loại này.
Sửa chữa những sai lầm trong quá trình sao chép DNA
Enzyme DNA polymerase đặc biệt đáng kinh ngạc đối với sự lựa chọn nucleotide của chúng trong quá trình tổng hợp DNA, đảm bảo rằng các bazơ được thêm vào một sợi đang phát triển, được ghép nối chính xác với phần bổ sung của chúng trên sợi khuôn (tức là A với T và C với G). Tuy nhiên, các enzyme này vẫn mắc lỗi với tỷ lệ khoảng 1 trên mỗi 100.000 nucleotide. Điều đó có vẻ không nhiều, cho đến khi bạn xem xét một tế bào có bao nhiêu DNA . Ở người, với 6 tỷ cặp cơ sở của chúng ta trong mỗi tế bào lưỡng bội, là các tế bào chứa đủ nhiễm sắc thể (chromosomes), con số đó sẽ lên tới khoảng 120.000 sai lầm mỗi khi tế bào phân chia.
May mắn thay, các tế bào đã phát triển các phương tiện rất phức tạp để sửa chữa hầu hết, nhưng không phải tất cả, những sai lầm đó. Một số lỗi được sửa chữa ngay lập tức trong quá trình sao chép thông qua một quá trình được gọi là hiệu đính và một số được sửa chữa sau khi sao chép trong một quá trình được gọi là sửa chữa không phù hợp .Khi một nucleotide không chính xác được thêm vào sợi đang phát triển, quá trình sao chép bị đình trệ do nhóm 3′-OH tiếp xúc của nucleotide ở vị trí “sai”.( Nhớ lại rằng [5] các nucleotide mới được thêm vào sợi đang phát triển trong quá trình sao chép bằng cách liên kết nhóm 5′-phosphate của chúng với nhóm 3′-OH của nucleotide trước đó trên sợi.) Trong quá trình đọc hiệu đính, các enzyme DNA polymerase nhận ra điều này và thay thế các nucleotide để quá trình nhân đôi được tiếp tục.Hiệu đính sửa chữa khoảng 99% các loại lỗi này, nhưng điều đó vẫn chưa đủ tốt để tế bào hoạt động bình thường.
Sau khi sao chép, sửa chữa không phù hợp làm giảm tỷ lệ lỗi cuối cùng thấp hơn nữa.Các nucleotide tạo cặp không chính xác gây ra dị dạng trong cấu trúc bậc hai của phân tử DNA cuối cùng.Trong quá trình sửa chữa không phù hợp, các enzyme nhận ra và sửa chữa những dị tật này bằng cách loại bỏ các nucleotide tạo cặp không chính xác và thay thế nó bằng nucleotide chính xác.
Khi lỗi sao chép trở thành đột biến
Các nucleotide tạo cặp không chính xác tồn tại sau quá trình sửa chữa không khớp sẽ trở thành đột biến vĩnh viễn sau lần phân bào tiếp theo . Điều này là do một khi những sai lầm như vậy được thiết lập, tế bào không còn nhận ra chúng là lỗi nữa. Hãy xem xét trường hợp lỗi sao chép gây ra bởi sự lung lay. Khi những sai lầm này không được sửa chữa, chuỗi DNA được giải trình tự không chính xác sẽ đóng vai trò là khuôn mẫu cho các sự kiện sao chép trong tương lai, khiến tất cả các cặp bazơ sau đó bị sai. Ví dụ, ở nửa dưới của Hình 2, sợi ban đầu có một cặp CG; sau đó, trong quá trình sao chép, cytosine (C) được kết hợp không chính xác với adenine(A) vì chao đảo. Trong ví dụ này, sự dao động xảy ra do A có thêm một nguyên tử hydro. Trong vòng phân chia tế bào tiếp theo, sợi đôi với sự tạo cặp CA sẽ tách ra trong quá trình sao chép, mỗi sợi đóng vai trò là khuôn mẫu để tổng hợp một phân tử DNA mới. Tại vị trí cụ thể đó, C sẽ bắt cặp với G, tạo thành một chuỗi xoắn kép có cùng trình tự với trình tự ban đầu (tức là trước khi xảy ra dao động), nhưng A sẽ bắt cặp với T, tạo thành phân tử DNA mới có cặp AT thay cho cặp CG ban đầu. Loại đột biến này được gọi là sự thay thế bazơ hay cặp bazơ. Sự thay thế bazơ liên quan đến việc thay thế một nhân purin cho một nhân purin khác hoặc một pyrimidine khác (ví dụ, một cặp AA không khớp, thay vì AT) được gọi là chuyển tiếp; sự thay thế một purine bằng một pyrimidine, hoặc ngược lại, được gọi là sự chuyển đổi .
Tương tự như vậy, khi lỗi sao chép đoạn trượt không được sửa chữa, chúng sẽ trở thành đột biến chèn và đột biến mất đoạn. Phần lớn các nghiên cứu ban đầu về đột biến trượt sợi được thực hiện bởi George Streisinger vào những năm 1970. Streisinger, một giáo sư tại Đại học Oregon và là một người yêu thích cá, được một số người gọi là “cha đẻ của ngành nghiên cứu cá ngựa vằn.” Tuy nhiên, ông cũng được biết đến với công trình nghiên cứu phage T4, một loại vi rút tấn công vi khuẩn. Streisinger đã sử dụng vi rút này để chỉ ra rằng hầu hết các đột biến chèn và xóa nucleotide xảy ra ở những vùng DNA chứa nhiều trình tự lặp lại (còn gọi là lặp lại song song), và ông đã đưa ra giả thuyết trượt sợi để giải thích tại sao lại như vậy (Streisinger et al., Năm 1966). (Trong Hình 3, lưu ý chuỗi chữ T lặp lại trên sợi khuôn nơi xảy ra trượt.) Khi trượt xảy ra, sự hiện diện của các cơ sở trùng lặp gần đó sẽ ổn định sự trượt để có thể tiến hành sao chép. Trong vòng sao chép tiếp theo, khi hai sợi tách rời nhau, việc chèn hoặc xóa tương ứng trên sợi khuôn hoặc sợi mồi sẽ được duy trì như một đột biến vĩnh viễn. Các nhà khoa học đã thu thập đủ bằng chứng để xác nhận giả thuyết về sự trượt sợi của Streisinger, và dạng đột biến gen này vẫn là một lĩnh vực nghiên cứu khoa học tích cực.
Một sơ đồ cho thấy hai hệ quả thay thế của sự trượt sợi.Ở đầu sơ đồ, một sợi đơn của DNA được hiển thị trong quá trình sao chép. Sợi DNA ban đầu, hoặc sợi khuôn, được mô tả như một hình chữ nhật màu xám nằm ngang. Một hình chữ nhật nằm ngang khác màu đỏ, đại diện cho sợi mới được tổng hợp, nằm phía trên và song song với sợi khuôn.Sợi mới được tổng hợp không dài như sợi khuôn, vì sợi khuôn chưa được sao chép hết hoàn toàn.Một mũi tên màu xám phân nhánh hướng từ sợi DNA đang sao chép tới hình minh họa ở phía bên trái của sơ đồ, có nhãn Tình huống một (scenario 1) và đến hình minh họa thứ hai ở phía bên phải của sơ đồ, có nhãn Tình huống hai (scenario 2). Trong tình huống một, sợi mới được tổng hợp thu được một nucleotide do sự trượt của sợi trong quá trình sao chép.

Hình 3: Sự trượt sợi trong quá trình nhân đôi DNA.
Khi hiện tượng trượt sợi xảy ra trong quá trình sao chép DNA, một sợi DNA có thể vòng ra ngoài, dẫn đến việc bổ sung hoặc xóa một nucleotide trên sợi mới được tổng hợp.
© 2014 Nature Education phỏng theo Pierce, Benjamin. Di truyền học: Phương pháp tiếp cận khái niệm , xuất bản lần thứ 2. Đã đăng ký Bản quyền.
Mặc dù hầu hết các đột biến được cho là do lỗi sao chép, chúng cũng có thể được gây ra bởi các thay đổi tự phát và cảm ứng về môi trường [6] đối với DNA xảy ra trước khi sao chép nhưng tồn tại giống như lỗi sao chép không sửa chữa. Cũng như lỗi sao chép, hầu hết các tổn thương DNA do môi trường gây ra đều được sửa chữa, dẫn đến ít hơn 1 trong số 1.000 tổn thương do hóa chất gây ra thực sự trở thành đột biến vĩnh viễn. Điều này cũng đúng với cái gọi là đột biến tự phát.”Tự phát” đề cập đến thực tế là các thay đổi xảy ra trong trường hợp không có hóa chất, bức xạ hoặc các thiệt hại môi trường khác.Thay vào đó, chúng thường được tạo ra bởi các phản ứng hóa học bình thường diễn ra trong tế bào, chẳng hạn như thủy phân. Các loại lỗi này bao gồm khử cặn, xảy ra khi liên kết nối giữa một nhân purin với đường deoxyribose của nó bị phá vỡ bởi một phân tử nước, dẫn đến một nucleotide không có nhân purin khiến không thể hoạt động như một khuôn mẫu trong quá trình sao chép DNA và quá trình khử amin , dẫn đến mất một nhóm amin từ một nucleotide, một lần nữa bằng phản ứng với nước. Một lần nữa, hầu hết các lỗi tự phát này đều được sửa chữa bằng các quá trình sửa chữa DNA.Nhưng nếu điều này không xảy ra, một nucleotide được thêm vào sợi mới được tổng hợp có thể trở thành một đột biến vĩnh viễn.
Ngay cả tỷ lệ đột biến thấp cũng có thể là nguyên nhân để lo ngại
Tỷ lệ đột biến về cơ bản khác nhau giữa các đơn vị phân loại, và thậm chí giữa các phần khác nhau của bộ gen trong một sinh vật . Các nhà khoa học đã báo cáo tỷ lệ đột biến thấp nhất là 1 sai lầm trên 100 triệu ( 10-8 ) đến 1 tỷ (10-9 ) nucleotide, chủ yếu ở vi khuẩn và cao nhất là 1 sai lầm trên 100 (10 -2 ) đến 1.000 (10-3 ) nucleotide, cái sau trong nhóm gen polymerase dễ mắc lỗi ở người (Johnson và cộng sự, 2000).
Ngay cả tỷ lệ đột biến thấp tới 10-10 cũng có thể tích lũy nhanh chóng theo thời gian, đặc biệt là ở các sinh vật sinh sản nhanh như vi khuẩn. Đây là một lý do tại sao việc lờn thuốc kháng sinh là một vấn đề sức khỏe cộng đồng hết sức quan trọng; xét cho cùng , các đột biến tích tụ trong một quần thể vi khuẩn cung cấp nhiều biến thể di truyền để thích nghi (hoặc đáp ứng) với áp lực chọn lọc tự nhiên do thuốc kháng khuẩn gây ra (Smolinski và cộng sự, 2003). Lấy ví dụ như E. coli . Bộ gen của vi khuẩn đường ruột phổ biến này có khoảng 4,2 triệu cặp bazơ, hay 8,4 triệu bazơ. Giả sử tỉ lệ đột biến là 10-9(tức là, con số giữa của các ước tính được báo cáo là 10-8 và 10-10 ), mỗi khi E. coli phân chia, trung bình mỗi tế bào con sẽ có 0,0084 đột biến mới. Hoặc, một cách nghĩ khác về nó là như thế này: Khoảng chừng 1% tế bào vi khuẩn sẽ chứa một đột biến mới. Điều đó có vẻ không nhiều. Tuy nhiên, vì vi khuẩn có thể phân chia nhanh gấp đôi mỗi giờ, nên một vi khuẩn đơn lẻ có thể phát triển thành một đàn gồm 1 triệu tế bào chỉ trong khoảng 10 giờ (220 = 1,048,576). Vào thời điểm đó, khoảng 10.000 vi khuẩn trong số này sẽ tích lũy ít nhất một đột biến. Khi số lượng vi khuẩn mang các đột biến khác nhau tăng lên, thì khả năng ít nhất một trong số chúng trở thành dạng kháng thuốc cũng tăng lên.
Tương tự như vậy, ở sinh vật đa bào, tế bào tích lũy các đột biến khi chúng phân chia. Ở người, nếu có đủ đột biến soma (tức là đột biến trong tế bào cơ thể chứ không phải tế bào trứng hoặc tinh trùng ) tích tụ trong suốt cuộc đời của một người, kết quả cuối cùng có thể là ung thư. Hoặc, ít thường xuyên hơn, một số đột biến ung thư được di truyền từ một hoặc cả hai cha mẹ; chúng thường được gọi là đột biến dòng mầm. Một trong những đột biến soma liên quan đến ung thư đầu tiên được phát hiện vào năm 1982, khi các nhà nghiên cứu phát hiện ra rằng một gen HRAS đột biến có liên quan đến ung thư bàng quang (Reddy và cộng sự , 1982). HRAS mã hóa cho một proteingiúp điều chỉnh sự phân chia tế bào. Kể từ đó, các nhà khoa học đã xác định được hàng trăm “gen ung thư” bổ sung. Một số trong số chúng, giống như một số đột biến dòng mầm liên quan đến một dạng ung thư đại trực tràng được gọi là ung thư đại trực tràng không nhiễm trùng di truyền (hereditary nonpolyposis colorectal cancer,HNPCC), đóng vai trò quan trọng trong việc sửa chữa DNA (Wijnen và cộng sự , 1998).
Tất nhiên, không phải tất cả các đột biến đều “xấu”[7]. Tuy nhiên, vì rất nhiều đột biến có thể gây ra ung thư, nên việc sửa chữa DNA rõ ràng là một đặc tính cực kỳ quan trọng của tế bào trong sinh vật đa bào .Tuy nhiên, quá nhiều điều tốt cũng có thể gây nguy hiểm.Nếu quá trình sửa chữa DNA là hoàn hảo và không có đột biến nào được tích lũy, thì sẽ không có biến thể di truyền – và biến thể này đóng vai trò là nguyên liệu thô cho quá trình tiến hóa. Do đó, các sinh vật thành công đã phát triển các phương tiện để sửa chữa DNA của chúng một cách hiệu quả nhưng không quá hiệu quả, chỉ để lại sự biến đổi gen vừa đủ để cho quá trình tiến hóa được tiếp tục.
./.
Nguồn:
https://www.nature.com/scitable/topicpage/dna-replication-and-causes-of-mutation-409/
Xem thêm: Những bài viết / dịch của Lê Nguyễn
***
Tham khảo:
[1]https://www.nature.com/scitable/topicpage/DNA-Damage-amp-Repair-Mechanisms-for-Maintaining-344
[2]https://www.nature.com/scitable/topicpage/Proto-Oncongenes-to-Oncogenes-to-Cancer-883
[3]https://www.nature.com/scitable/topicpage/Discovery-of-DNA-Structure-and-Function-Watson-397
[4]http://www.nature.com/nature_education
[5]https://www.nature.com/scitable/topicpage/Major-Molecular-Events-of-DNA-Replication-413
[6]https://www.nature.com/scitable/topicpage/Environmental-Influences-on-Gene-Expression-536
[7]https://www.nature.com/scitable/topicpage/Genetic-Mutation-441
Tài liệu tham khảo và bài đọc thêm
Crick, FHS Ghép cặp Codon-anticodon: Giả thuyết lung lay. Journal of Molecular Biology19 , 548–555 (1966) ( liên quan đến bài báo )
